BTE is a python module for automated extraction of body text from web pages. It can also be used to generate short teasers/summaries. download
BTE extracts the main body of text from a web page. It does this by tokenising the document and performing some shallow processing. The html document is tokenised and represented as a binary string where a 0 represents a tag token and a 1 represents a text token.
If we graph cumulative total tokens on the x axis and cumulative tag tokens on the y axis we get a graph something like that shown below.
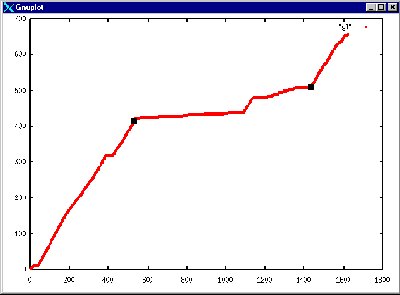
BTE basically works by finding an i and j where we maximise the number of text tokens between i and j and maximise the number of tag tokens below i and above j.
BTE can also be used to generate summaries/teasers of news articles as the start of the body text often contains a summary of the article.
Installation:
----------------
Just copy the python file into a location in your python path
Usage:
-------------------
import sys,BodyTextExtractor
html = open(sys.argv[1]).read()
p = BodyTextExtractor.HtmlBodyTextExtractor()
p.feed(html)
p.close()
x = p.body_text()
s = p.summary()
t = p.full_text()
print "\n\nSummary:\n",s
print "\nBodytext:\n",x
print "\nFulltext:\n",t
Copyright:
-------------
This software is distributed under the GNU public license. Please read
the file LICENCE.